


Double-Checked Locking in Java
Double-Checked Locking ist ein Pattern, um in Multithreading-Umgebungen Objekte lazily (also beim ersten Zugriff darauf) zu initialisieren, ohne dass es dabei zu subtilen Race Conditions kommen kann – und das ohne den Zugriff auf dieses Objekt vollständig (und damit zeitaufwändig) zu synchronisieren.
In diesem Artikel erfährst du:
- Was ist die Motivation für das Double-Checked Locking?
- Welche subtilen Fehler können bei der „Lazy Initialization“ gemacht werden?
- Warum ist die vollständige Synchronisierung mit „synchronized“ nicht optimal?
- Warum ist das originale Double-Checked Locking Idiom fehlerhaft?
- Wie wird Double-Checked Locking in Java korrekt implementiert?
- Welche Alternativen gibt es?
Motivation
Gelegentlich möchten wir ein Objekt erst dann initialisieren, wenn es benötigt wird, da die Initialisierung aufwändig ist und wir den Programmstart nicht unnötig verzögern wollen.
In single-threaded Anwendungen ist das einfach. Beispielsweise könnten wir das Laden von Einstellungen aus der Datenbank beim ersten Zugriff darauf wie folgt implementieren:
private Settings settings;
private Settings getSettings() {
if (settings == null) {
settings = loadSettingsFromDatabase();
}
return settings;
}Code-Sprache: Java (java)Beim ersten Aufruf der Methode werden die Settings geladen und im settings-Feld gespeichert. Bei jedem weiteren Aufruf wird das im settings-Feld gespeicherte Objekt zurückgegeben.
Diese Methode ist jedoch nicht threadsicher.
Es gibt drei problematische Effekte, die beim Aufruf dieser Methode aus mehreren gleichzeitig laufenden Threads auftreten kann – einen offensichtlichen und zwei, die selbst erfahrene Java-EntwicklerInnen oft übersehen.
Effekt 1: Mehrfache Initialisierung durch Verzahnung der Thread-Ausführungen
Ein Effekt, den die meisten Java Developer sofort sehen, ist der folgende:
Würde die Methode aus zwei Threads gleichzeitig aufgerufen werden, kann sich die Ausführung der zwei Threads wie folgt verzahnen:
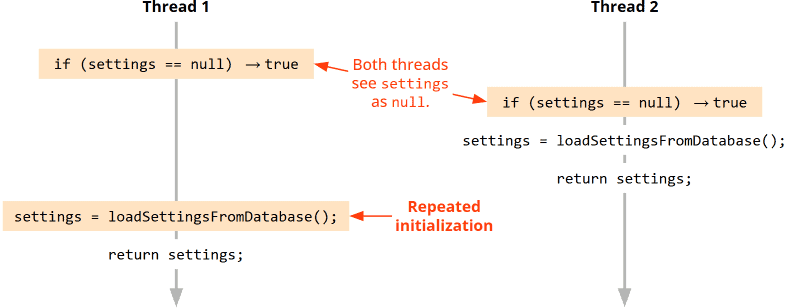
Vereinfacht gesagt:
Wenn beide Threads die Methode nahezu gleichzeitig starten, sehen beide, dass settings null ist. Dementsprechend würden beide Threads die Settings aus der Datenbank laden, und die als zweites geladenen Settings würden die zuerst geladenen überschreiben.
Effekt 2: Mehrfache Initialisierung durch Cache-Effekte
Was selbst erfahrene EntwicklerInnen oft nicht sehen, ist folgendes:
Tatsächlich muss die Thread-Ausführung nicht einmal verzahnt sein. Auch wenn ein Thread die Methode erst dann ausführt, nachdem der andere sie beendet hat, kann es zu mehrfacher Initialisierung kommen:

Wie kann das sein? Wieso sollte Thread 2 settings als null sehen und die Initialisierung wiederholen?
Die Antwort liegt in der CPU-Architektur:
Jeder CPU-Kern hat einen Cache, in dem Daten aus dem Hauptspeicher zwischengespeichert werden. Genauer gesagt: Bei modernen CPUs hat jeder Kern sogar zwei Caches: einen Level-1-Cache und einen Level-2-Cache. Zudem hat die CPU noch einen von allen Kernen geteilten Level-3-Cache:
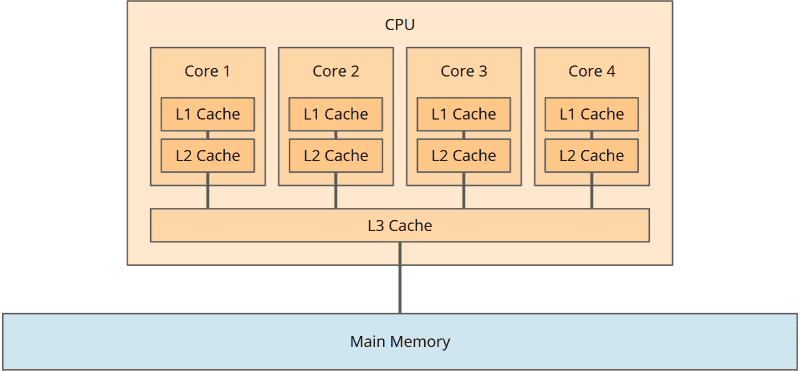
Die Aufteilung auf drei Cache-Level können wir für die Betrachtung der Auswirkungen der Caches allerdings vernachlässigen, und daher werde ich im folgenden nur vom CPU-Kern-Cache sprechen.
Aus Performancegründen arbeitet jeder CPU-Kern vorrangig mit seinem Cache.
Nehmen wir an, Thread 1 und Thread 2 laufen auf unterschiedlichen CPU-Kernen – der Einfachheit halber: CPU-Kern 1 und CPU-Kern 2. Dann könnte folgendes passieren:
- Thread 1 hat das
settings-Feld bisher nur in den Cache von CPU-Kern 1 geschrieben, aber noch nicht in den Hauptspeicher. Thread 2 lädt dassettings-Feld aus dem Hauptspeicher, wo es nochnullist. Demzufolge sieht Thread 2 es alsnullund initialisiert es erneut. - Oder: Thread 1 schreibt das
settings-Feld zwar in den Hauptspeicher, aber CPU-Kern 2 hat das Feld bereits zuvor, als es nochnullwar, in seinen Cache geladen. Thread 2 greift nun auf dieses gecachte Feld zu – sieht also auch in diesem Fallnullund initialisiert die Settings erneut.
Race Conditions
Beide Effekte – sowohl das wiederholte Laden durch Verzahnung der Thread-Ausführungen als auch das wiederholte Laden durch Cache-Effekte – treten nicht deterministisch auf, da nicht vorhersehbar ist, wie Threads zeitlich ablaufen und wann die CPU den Cache mit dem Hauptspeicher synchronisiert. Es handelt sich daher um sogenannte „Race Conditions“.
D. h. dass die Software unter Umständen monatelang korrekt läuft, bis es zu einem Fehler kommt. Es ist dann extrem schwer, den Fehler zu reproduzieren, ihn aufzuspüren und zu beheben.
Und wenn uns die wiederholte Initialisierung nicht stört?
Wenn diese Race Condition nur alle paar Monate auftritt und die einzige Folge ist, dass die Einstellungen wiederholt aus der Datenbank geladen werden – könnten wir das nicht einfach ignorieren?
Zum einen: In diesem konkreten Use Case vermutlich schon. Es gibt aber auch Use Cases, in denen eine wiederholte Initialisierung ernste Konsequenzen haben könnte. Beispielsweise, wenn das so initialisierte Objekt einen globalen Status kapselt, auf den auch schreibend zugegriffen wird. In so einem Use Case müssen wir sicherstellen, dass zu jeder Zeit nur eine Instanz existiert.
Zum anderen: Ich habe oben erwähnt, dass es neben dem offensichtlichen Effekt der unglücklichen Thread-Verzahnung zwei subtile Effekte gibt. Der eine war das CPU Core Caching.
Bevor ich auf den zweiten subtilen Effekt näher eingehe, zeige ich dir zunächst die naheliegendste (aber auch unperformanteste) Lösung, um diese Methode threadsicher zu machen.
Danach zeige ich dir das „originale“ Double-Checked Locking, das diese unperformante Lösung performanter machen soll. Leider enthält das „originale“ Double-Checked Locking immer noch den zweiten subtilen Effekt.
Dann werde ich diesen Effekt erklären und dir zeigen, wie du Double-Checked Locking in Java korrekt und performant implementierst.
Unperformanteste Lösung: Vollständige Synchronisation
Die naheliegendste Variante, um die getSettings()-Methode threadsicher zu machen, ist sie mit dem synchronized-Keyword (oder alternativ einem expliziten Lock) zu synchronisieren:
// ↓
private synchronized Settings getSettings() {
if (settings == null) {
settings = loadSettingsFromDatabase();
}
return settings;
}Code-Sprache: Java (java)Das bedeutet allerdings, dass bei jedem Zugriff auf die Einstellungen eine vollständige Synchronisation durchgeführt wird, d. h. dass ggf. gewartet werden muss, falls gerade ein anderer Thread die Methode blockiert, dass dann der Zugriff für andere Threads blockiert wird und dass beim Betreten und Verlassen des synchronized-Blocks alle Daten zwischen CPU-Cache und Hauptspeicher synchronisisert werden.
Dieser Vorgang ist recht aufwändig und daher inbesondere für häufig aufgerufene Methoden nicht zu empfehlen.
Das „originale“ Double-Checked Locking
Oft versuchen Entwickler, den Code zu optimieren, indem sie zunächst prüfen, ob das settings-Feld bereits gesetzt ist, und nur dann den synchronisierten Block betreten, wenn das Feld noch null ist und dementsprechend initialisiert werden muss.
Für den Fall, dass nach der ersten Prüfung – aber vor dem Betreten des synchronized-Blocks – ein anderer Thread das settings-Feld gesetzt hat, wird innerhalb des synchronized-Blocks ein zweites Mal geprüft, ob dieses null ist. Daher die Bezeichnung „Double-Checked Locking“ (auf deutsch: „Doppelt überprüfte Sperrung“):
// Don't do this!!!
// This is the original, broken implementation of the "Double-Checked Locking" idiom.
private Settings settings;
private Settings getSettings() {
if (settings == null) {
synchronized (this) {
if (settings == null) {
settings = loadSettingsFromDatabase();
}
}
}
return settings;
}Code-Sprache: Java (java)Auf den ersten Blick scheint dies eine sinnvolle Lösung zu sein, da so – außer beim ersten Aufruf – keine teure Synchronisation stattfinden muss. Doch wie der Kommentar in den ersten Zeilen des Codes bereits offenbart, ist diese Implementierung fehlerhaft.
Und damit kommen wir zum dritten Effekt.
Effekt 3: Instruction Reordering
„Instruction Reordering“ bedeutet, dass sowohl Compiler als auch CPU innerhalb eines Threads zur Performance-Optimierung CPU-Instruktionen umsortieren dürfen, d. h. in einer anderen Reihenfolge ausführen dürfen – solange das die Semantik der Programmausführung innerhalb dieses Threads nicht verändert.
Beispielsweise könnte der Code int a = 3; int b = 4; int c = a + b; auch so compiliert oder ausgeführt werden, dass zuerst Variable b auf 4 gesetzt wird und danach Variable a auf 3. Für die Berechnung von c macht das keinen Unterschied:

Was hat das mit der Initialisierung des settings-Felds zu tun?
Der oben gezeigte Java-Programmcode wird sinngemäß in die folgenden Instruktionen übersetzt:
- Lade die Einstellungen aus der Datenbank.
- Erzeuge ein neues
Settings-Objekt. - Initialisiere das
Settings-Objekt mit den aus der Datenbank geladenen Werten. - Weise dieses
Settings-Objekt demsettings-Feld zu. - Lese Einstellungen aus dem
settings-Feld
(dieser Schritt ist im Beispielcode oben nicht zu sehen).
Der Java-Compiler darf diese Instruktionen umordnen, insbesondere darf er die Schritte 3 und 4 vertauschen:
- Lade die Einstellungen aus der Datenbank.
- Erzeuge ein neues
Settings-Objekt. - Weise dieses
Settings-Objekt demsettings-Feld zu. - Initialisiere das
Settings-Objekt mit den aus der Datenbank geladenen Werten. - Lese Einstellungen aus dem
settings-Feld.
Das Settings-Objekt wird also zuerst (im uninitialisierten Zustand) dem Feld zugewiesen und erst danach initialisiert. Innerhalb eines Threads spielt das keine Rolle, da Schritt 5 (der lesende Zugriff) immer noch nach der Initialisierung ausgeführt wird.
Aber: Wenn wir das noch einmal im Kontext der verzahten Thread-Ausführung betrachten, wäre jetzt folgender Ablauf möglich:

Was passiert hier?
Thread 1 sieht das uninitialisierte settings-Feld, lädt die Einstellungen aus der Datenbank, erzeugt ein Settings-Objekt und weist dieses dem settings-Feld zu – und zwar bevor es initialisiert ist. CPU-Kern 1 speichert zufällig in diesem Moment das settings-Feld im Hauptspeicher.
Genau jetzt lädt CPU-Kern 2 das settings-Feld aus dem Hauptspeicher. Und da dieses nicht null ist, versucht Thread 2 nicht, den synchronized-Block zu betreten, merkt dementsprechend auch nicht, dass Thread 1 die Initialisierung noch nicht abgeschlossen hat.
Und somit sieht Thread 2 zu diesem Zeitpunkt uninitialisierte Einstellungen (d. h. beispielsweise int-Felder, die noch auf 0 stehen, oder String-Felder, die noch null sind).
Das passiert natürlich nicht immer, sondern nur dann, wenn die Ausführung der zwei Threads und die Synchronisation zwischen CPU-Kern-Cache und Hauptspeicher exakt so verzahnt abläuft, wie oben dargestellt. Auch mit fehlerhaftem Double-Checked Locking kann die Anwendung monatelang korrekt laufen, bis es zu einem Fehler kommt. Doch dann wird es quasi unmöglich sein, den Fehler zu reproduzieren – und dementsprechend schwer, ihn aufzuspüren und zu beheben.
Auch bei der nicht synchronisierten Version vom Beginn des Artikels kann diese Race Condition auftreten. D. h. die Frage von oben („Und wenn uns die wiederholte Initialisierung nicht stört?“) müssen wir damit beantworten, dass wir selbst dann den Zugriff auf das gemeinsam genutzte Feld geeignet synchronisieren müssen.
Warum überhaupt CPU-Kern-Cache und Instruction Reordering?
Jetzt stellt sich berechtigterweise die Frage:
Warum wird der CPU-Kern-Cache überhaupt verwendet, und warum erlaubt Java „Instruction Reordering“, wenn das doch zu so vielen Problemen führen kann?
Die Antwort liegt in der Grundannahme, auf der CPU-Architekturen und Compiler basieren:
Anwendungen sollen so performant wie möglich ablaufen, und bei Multithreading-Anwendungen wird davon ausgegangen, dass per default Threads unabhängig voneinander sind und deren Performance jeweils einzeln optimiert werden soll.
Zugriff auf gemeinsam genutzte Datenstrukturen ist die Ausnahme und muss vom Programmierer durch geeignete Maßnahmen synchronisiert werden.
Das „originale“ Double-Checked Locking ist – wie wir nun gesehen haben – keine geeignete Maßnahme. Wie macht man es nun richtig?
Korrektes Double-Checked Locking in Java
Vor Java 5 gab es keine Möglichkeit, das Double-Checked Locking korrekt in Java umzusetzen. Ab Java 5 ist dies mit einem einzigen zusätzlichen Keyword möglich: volatile.
Hier ist eine korrekte (noch nicht optimierte) Version des Double-Checked Locking Idioms in Java:
// Correct - but not yet optimized - version of the "Double-Checked Locking" idiom
private volatile Settings settings; // ⟵ `settings` field must be volatile!
private Settings getSettings() {
if (settings == null) {
synchronized (this) {
if (settings == null) {
settings = loadSettingsFromDatabase();
}
}
}
return settings;
}Code-Sprache: Java (java)Was macht volatile, und warum ist das Double-Checked Locking damit korrekt?
Mit dem Keyword volatile zeigen wir an, dass der Wert eines Feldes von verschiedenen Threads geändert werden kann. Damit erreichen wir zwei Dinge:
- Zwischen Schreiben und nachfolgendem Lesen eines Feldes werden die Caches der beteiligten CPU-Kerne mit dem Hauptspeicher synchronisiert. Somit sind Änderungen an einem Feld immer für andere Threads sichtbar – Thread-Caching-Probleme werden so verhindert.
- Ein neu erzeugtes Objekt wird erst dann einem Feld zugewiesen, wenn es vollständig initialisiert ist – damit kann ein Thread nie ein unvollständig initialisiertes Objekt aus einem anderen Thread sehen.
Was bedeutet das konkret für das Double-Checked Locking?
Durch volatile wird sichergestellt, dass im vorherigen Beispiel kein Instruction Reordering bzgl. der Objekt-Initialisierung durchgeführt wird, d. h. die Schritte 3 und 4 dürfen nicht vertauscht werden. Somit ist die oben dargestellte, zu einer Race Condition führende Thread-Verzahnung nicht mehr möglich.
Optimiertes Double-Checked Locking in Java
volatile führt allerdings auch dazu, dass, nachdem settings initialisiert wurde, bei jedem Aufruf der getSettings()-Methode zwei Mal der CPU-Cache mit dem Hauptspeicher synchronisiert wird – denn es wird zwei Mal auf das settings-Feld zugegriffen: einmal bei der Prüfung auf null und einmal bei der Rückgabe mit return.
Das können wir optimieren, indem wir das Feld settings zunächst einer lokalen Variable zuweisen. Diese kann, da jeder Thread seine eigene lokale Version diese Variablen hat, auf dem Thread-Stack gehalten werden und muss nicht mit dem Hauptspeicher synchronisiert werden:
// Correct and optimized version of the "Double-Checked Locking" idiom
private volatile Settings settings;
private Settings getSettings() {
Settings localRef = settings; // ⟵ Store `settings` in a thread-local variable
if (localRef == null) {
synchronized (this) {
localRef = settings;
if (localRef == null) {
settings = localRef = loadSettingsFromDatabase();
}
}
}
return localRef; // ⟵ Return thread-local variable
// without accessing main memory a second time
}Code-Sprache: Java (java)Im regulären Fall, also wenn settings bereits initialisiert ist, wird so nur noch einmal auf den Hauptspeicher zugegriffen: beim Zuweisen von localRef auf settings. Die Rückgabe mit return greift dann nur noch auf die Thread-lokale Variable localRef zu.
Klingt kompliziert?
Ist es auch! Und damit besteht auch immer das Risiko einer fehlerhaften Implementierung.
Für die Initialisierung von zumindest statischen Feldern gibt es eine weitere Variante: das Initialization-on-Demand Holder Idiom – aber auch das ist eher ein Workaround als eine Lösung.
Geht das nicht schöner?
Bald! In Java 25 werden die sogenannten Stable Values eingeführt, allerdings zunächst als Preview-Version. Stable Values sind ein Wrapper, der die threadsichere Initialisierung von gemeinsam genutzten Werten hinter einer einfachen API kapselt.
Bis Stable Values finalisiert werden, müssen wir uns allerdings zwischen einer vollständigen Synchronisation (einfach in der Implementierung, dafür langsam) und einem korrekt implementierten Double-Checked Locking (schnell, dafür kompliziert und fehleranfällig in der Implementierung) entscheiden.
Fazit
Die Initialisierung von gemeinsam genutzten Objekten beim ersten Zugriff darauf kann in Multithreading-Anwendungen (bisher) nur durch vollständige Synchronisation (mit synchronized oder einem expliziten Lock), durch ein korrekt implementiertes Double-Checked Locking oder durch das Initialization-on-Demand Holder Idiom implementiert werden.
Beim Double-Checked Locking ist es essentiell, das gemeinsam genutzte Feld als volatile zu markieren, um Race Conditions auszuschließen, die durch Thread-Caching-Effekte oder Instruction Reordering verursacht werden.
In Java 25 werden die sogenannten Stable Values eingeführt: ein threadsicherer und Performance-optimierter Wrapper für Objekte, die beim ersten Zugriff initialisiert werden sollen.
Wenn dir der Artikel weitergeholfen hat, würde ich mich sehr über eine positive Bewertung auf meinem ProvenExpert-Profil freuen. Dein Feedback hilft mir, meine Inhalte weiter zu verbessern und motiviert mich, neue informative Artikel zu schreiben.
Möchtest du informiert werden, wenn neue Artikel auf HappyCoders.eu veröffentlicht werden? Dann klicke hier, um dich für den HappyCoders.eu-Newsletter anzumelden.