


Double-Checked Locking in Java
Double-Checked Locking is a pattern used to lazily initialize objects (i.e., upon first access) in multi-threading environments without the risk of subtle race conditions – and without fully (and thus time-consumingly) synchronizing access to this object.
In this article you will find out:
- What is the motivation for Double-Checked Locking?
- What subtle errors can be made with “Lazy Initialization”?
- Why is full synchronization with
synchronizednot optimal? - Why is the original Double-Checked Locking idiom flawed?
- How is Double-Checked Locking correctly implemented in Java?
- What alternatives are there?
Motivation
Occasionally, we want to initialize an object only when it’s needed, as initialization is costly and we don’t want to unnecessarily delay program startup.
In single-threaded applications, this is simple. For example, we could implement loading settings from the database on first access as follows:
private Settings settings;
private Settings getSettings() {
if (settings == null) {
settings = loadSettingsFromDatabase();
}
return settings;
}Code language: Java (java)On the first method call, the settings are loaded and stored in the settings field. On each subsequent call, the object stored in the settings field is returned.
However, this method is not thread-safe.
There are three problematic effects that can occur when this method is called from multiple concurrently running threads – one obvious and two that even experienced Java developers often overlook.
Effect 1: Multiple Initialization Due to Thread Execution Interleaving
An effect that most Java developers immediately see is the following:
If the method were called simultaneously from two threads, the execution of the two threads could interleave as follows:
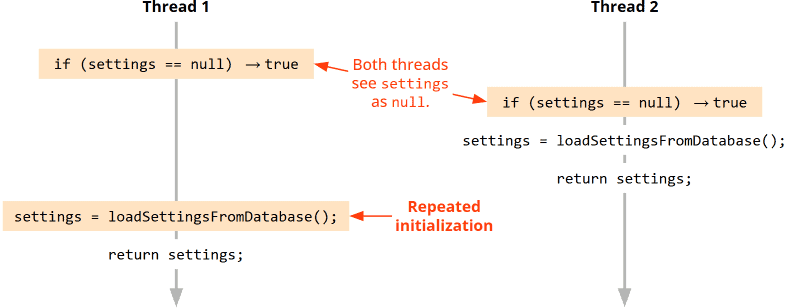
Simply put:
If both threads start the method almost simultaneously, both see that settings null is null. Consequently, both threads would load the settings from the database, and the settings loaded second would overwrite those loaded first.
Effect 2: Multiple Initialization Due to Cache Effects
What even experienced developers often don’t see is this:
In fact, the thread execution doesn’t even need to be interleaved. Even if one thread executes the method only after the other has finished it, multiple initialization can occur:

How can this be? Why would thread 2 see settings as null and repeat the initialization?
The answer lies in the CPU architecture:
Each CPU core has a cache where data from main memory is temporarily stored. More precisely: In modern CPUs, each core even has two caches: a level 1 cache (L1) and a level 2 cache (L2). Additionally, the CPU has a level 3 cache (L3) shared by all cores:
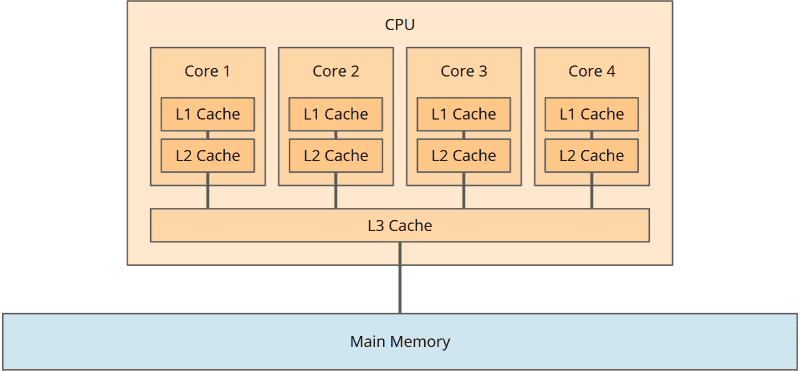
We can disregard the division into three cache levels when considering the effects of caches, so I will only refer to the CPU core cache in the following.
For performance reasons, each CPU core primarily works with its cache.
Let’s assume thread 1 and thread 2 run on different CPU cores – for simplicity: CPU core 1 and CPU core 2. Then the following could happen:
- Thread 1 has so far only written the
settingsfield to the cache of CPU core 1, but not yet to main memory. Thread 2 loads thesettingsfield from main memory, where it is stillnull. Consequently, thread 2 sees it asnulland initializes it again. - Or: thread 1 writes the
settingsfield to main memory, but CPU core 2 has already loaded the field into its cache when it was stillnull. Thread 2 now accesses this cached field – so in this case also seesnulland reinitializes the settings.
Race Conditions
Both effects – both repeated initialization due to thread execution interleaving and repeated initialization due to cache effects – do not occur deterministically, as it’s not predictable how threads will run temporally and when the CPU will synchronize the cache with main memory. These are therefore called “race conditions”.
This means that the software may run correctly for months until an error occurs. It is then extremely difficult to reproduce the error, track it down, and fix it.
And what if we don’t mind the repeated initialization?
If this race condition only occurs every few months and the only consequence is that the settings are repeatedly loaded from the database – couldn’t we simply ignore it?
On one hand: In this specific use case, probably yes. However, there are also use cases where repeated initialization could have serious consequences. For example, if the initialized object encapsulates a global state that is also accessed for writing. In such a use case, we must ensure that only one instance exists at any given time.
On the other hand: I mentioned above that besides the obvious effect of the unfortunate thread interleaving, there are two subtle effects. One was CPU core caching.
Before I go into more detail about the second subtle effect, I’ll first show you the most obvious (but also least performant) solution to make this method thread-safe.
After that, I’ll show you the “original” double-checked locking, which is supposed to make this unperformant solution more performant. Unfortunately, the “original” double-checked locking still contains the second subtle effect.
Then I will explain this effect and show you how to correctly and efficiently implement double-checked locking in Java.
Least Performant Solution: Complete Synchronization
The most obvious way to make the getSettings() method thread-safe is to synchronize it with the synchronized keyword (or alternatively with an explicit lock):
// ↓
private synchronized Settings getSettings() {
if (settings == null) {
settings = loadSettingsFromDatabase();
}
return settings;
}Code language: Java (java)However, this means that every access to the settings requires a complete synchronization, i.e., potentially waiting if another thread is currently blocking the method, then blocking access for other threads, and synchronizing all data between CPU cache and main memory when entering and leaving the synchronized block.
This process is quite costly and therefore not recommended, especially for frequently called methods.
The “Original” Double-Checked Locking
Developers often try to optimize the code by first checking if the settings field is already set, and only entering the synchronized block if the field is still null and therefore needs to be initialized.
In case after the first check – but before entering the synchronized block – another thread has set the settings field, it is checked a second time within the synchronized block whether it is null. Hence the term “Double-Checked Locking”:
// Don't do this!!!
// This is the original, broken implementation of the "Double-Checked Locking" idiom.
private Settings settings;
private Settings getSettings() {
if (settings == null) {
synchronized (this) {
if (settings == null) {
settings = loadSettingsFromDatabase();
}
}
}
return settings;
}Code language: Java (java)At first glance, this seems to be a sensible solution, as no expensive synchronization is necessary – except for the first call. But as the comment in the first lines of the code already reveals, this implementation is flawed.
And this brings us to the third effect.
Effect 3: Instruction Reordering
“Instruction Reordering” means that both compilers and CPUs are allowed to reorder CPU instructions within a thread for performance optimization, i.e., execute them in a different order – as long as it doesn’t change the semantics of program execution within this thread.
For example, the code int a = 3; int b = 4; int c = a + b; could also be compiled or executed so that variable b is set to 4 first and then variable a to 3. For the calculation of c, it makes no difference:

What does this have to do with initializing the settings field?
The Java program code shown above is essentially translated into the following instructions:
- Load the settings from the database.
- Create a new
Settingsobject. - Initialize the
Settingsobject with the values loaded from the database. - Assign this
Settingsobject to thesettingsfield. - Read settings from the
settingsfield
(this step is not visible in the example code above).
The Java compiler is allowed to reorder these instructions, especially it may swap steps 3 and 4:
- Load the settings from the database.
- Create a new
Settingsobject. - Assign this
Settingsobject to thesettingsfield. - Initialize the
Settingsobject with the values loaded from the database. - Read settings from the
settingsfield.
So the Settings object is first assigned to the field (in an uninitialized state) and only then initialized. Within a single thread, this doesn’t matter, as step 5 (the read access) is still executed after the initialization.
But: If we consider this again in the context of interleaved thread execution, the following sequence would now be possible:

What happens here?
Thread 1 sees the uninitialized settings field, loads the settings from the database, creates a Settings object and assigns it to the settings field – before it is initialized. CPU core 1 coincidentally stores the settings field in main memory at this moment.
Right now, CPU core 2 loads the settings field from main memory. And since this is not null, thread 2 does not attempt to enter the synchronized block, and consequently does not notice that thread 1 has not yet completed the initialization.
And thus, thread 2 sees uninitialized settings at this point (i.e., for example, int fields that are still set to 0, or string fields that are still null).
Of course, this doesn’t happen always, but only when the execution of the two threads and the synchronization between CPU core cache and main memory occurs exactly as interleaved as shown above. Even with faulty Double-Checked Locking, the application can run correctly for months until an error occurs. But then it will be virtually impossible to reproduce the error – and correspondingly difficult to track down and fix.
This race condition can also occur with the non-synchronized version from the beginning of the article. I.e., we must answer the question from above (“And what if we don’t mind the repeated initialization?”) by saying that even then we must appropriately synchronize access to the shared field.
Why CPU Core Cache and Instruction Reordering at all?
Now the legitimate question arises:
Why is the CPU core cache used at all, and why does Java allow “Instruction Reordering” if it can lead to so many problems?
The answer lies in the basic assumption on which CPU architectures and compilers are based:
Applications should run as performantly as possible, and with multithreading applications, it is assumed that by default, threads are independent of each other and their performance should be optimized individually.
Access to shared data structures is the exception and must be synchronized by the programmer through appropriate measures.
The “original” Double-Checked Locking is – as we have now seen – not an appropriate measure. So how do you do it correctly?
Correct Double-Checked Locking in Java
Before Java 5, there was no way to implement Double-Checked Locking correctly in Java. From Java 5 onwards, this is possible with a single additional keyword: volatile.
Here is a correct (not yet optimized) version of the Double-Checked Locking idiom in Java:
// Correct – but not yet optimized – version of the "Double-Checked Locking" idiom
private volatile Settings settings; // ⟵ `settings` field must be volatile!
private Settings getSettings() {
if (settings == null) {
synchronized (this) {
if (settings == null) {
settings = loadSettingsFromDatabase();
}
}
}
return settings;
}Code language: Java (java)What does volatile do, and why is Double-Checked Locking correct with it?
With the keyword volatile, we indicate that the value of a field can be changed by different threads. This achieves two things:
- Between writing and subsequent reading of a field, the caches of the involved CPU cores are synchronized with the main memory. Thus, changes to a field are always visible to other threads – thread caching problems are prevented this way.
- A newly created object is only assigned to a field when it is fully initialized – thus a thread can never see an incompletely initialized object from another thread.
What does this mean specifically for Double-Checked Locking?
volatile ensures that in the previous example, no instruction reordering is performed with respect to object initialization, i.e., steps 3 and 4 must not be swapped. Thus, the thread interleaving leading to a race condition, as shown above, is no longer possible.
Optimized Double-Checked Locking in Java
volatile however, also causes that, after settings has been initialized, every call to the getSettings() method synchronizes the CPU cache with the main memory twice – because the settings field is accessed twice: once when checking for null and once when returning with return.
We can optimize this by first assigning the field settings to a local variable. Since each thread has its own local version of this variable, it can be kept on the thread stack and does not need to be synchronized with main memory:
// Correct and optimized version of the "Double-Checked Locking" idiom
private volatile Settings settings;
private Settings getSettings() {
Settings localRef = settings; // ⟵ Store `settings` in a thread-local variable
if (localRef == null) {
synchronized (this) {
localRef = settings;
if (localRef == null) {
settings = localRef = loadSettingsFromDatabase();
}
}
}
return localRef; // ⟵ Return thread-local variable
// without accessing main memory a second time
}Code language: Java (java)In the regular case, i.e., when settings is already initialized, there is now only one access to main memory: when assigning localRef to settings. Returning it then only accesses the thread-local variable localRef.
Sounds complicated?
It is! And thus there’s always a risk of faulty implementation.
For initializing at least static fields, there’s another variant: the Initialization-on-Demand Holder Idiom – but this is also more of a workaround than a solution.
Isn’t there a nicer way?
Soon! In Java 25, so-called Stable Values will be introduced, initially as a preview version. Stable Values are a wrapper that encapsulates the thread-safe initialization of shared values behind a simple API.
Until Stable Values are finalized, we must choose between full synchronization (simple in implementation, but slow) and a correctly implemented Double-Checked Locking (fast, but complicated and error-prone in implementation).
Conclusion
The initialization of shared objects upon first access in multithreading applications can (so far) only be implemented through full synchronization (with synchronized or an explicit lock), through a correctly implemented Double-Checked Locking, or through the Initialization-on-Demand Holder Idiom.
With Double-Checked Locking, it’s essential to mark the shared field as volatile to eliminate race conditions caused by thread caching effects or instruction reordering.
In Java 25, so-called Stable Values will be introduced: a thread-safe and performance-optimized wrapper for objects that should be initialized upon first access.
If this article has helped you, I would greatly appreciate a positive review on my ProvenExpert profile. Your feedback helps me improve my content and motivates me to write new informative articles.
Would you like to be informed when new articles are published on HappyCoders.eu? Then click here to sign up for the HappyCoders.eu newsletter.