


Java Compact Object Headers
(JEP 450)
Every Java object has an object header that precedes the actual data in memory. The header mainly contains the hash code of the object and the information on which class the object is an instance of.
As of Java 24, the object header is 96 bits (12 bytes) in size – or 128 bits (16 bytes) if Compressed Class Pointers are switched off (although there is almost no reason to do so).
As part of Project Lilliput, the JDK developers have been working for many years on ways to compress the header to a total of 64 bits or even 32 bits.
In Java 24, the time had come: JDK Enhancement Proposal 450 introduced so-called “Compact Object Headers” – for now in “experimental” status. Compact Object Headers make it possible to compress the object header from 96 bits to 64 bits and thus significantly reduce the heap size of existing applications.
In this article you will find out:
- How does header compression work?
- Why does this not only reduce memory requirements but also increase application performance?
Status Quo
You can find a detailed description of the structure of object headers in the main article on Java object headers. Here is a summary of the most essential points:
The object header usually consists of a 64-bit “Mark Word” and a 32-bit “Class Word”. Mark Word and Class Word are structured as follows:
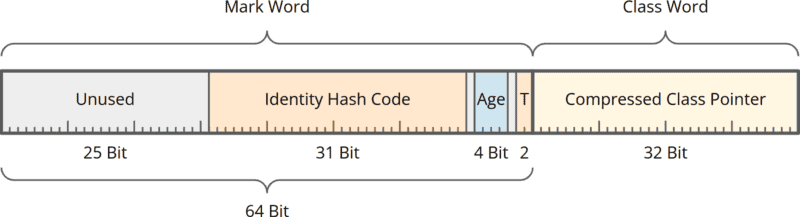
The Mark Word contains:
- a 31-bit identity hash code (which is returned by the
System.identityHashCode(Object)method), - 4 bits in which the garbage collector stores the age of an object (based on which it decides when to move an object from the young to the old generation),
- 2 “tag bits” that indicate whether the object is not locked, locked uncontended (without waiting threads), or locked contended (with waiting threads).
The Class Word contains a 32-bit offset in the maximum 4 GB compressed class space to a so-called class data structure containing all relevant data about the object’s class.
From Compressed Class Pointer to Compact Object Header
How can we further compress the object header based on Compressed Class Pointers?
First of all, the Mark Word (as you can see above) currently contains 27 unused bits (25 at the beginning and one each before and after the “age bits”). That means that of the 96 bits of the entire object header, only 96 - 27 = 69 bits are required. To get to 64 bits, we must somehow save five bits.
Where can we get them?
The JDK developers experimented for a long time until they came up with the following solution (I changed the scale for better visualization – the 64 bits now cover the entire width):
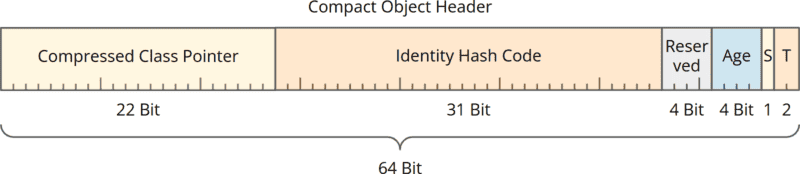
The new 64-bit header is no longer divided into Mark Word and Class Word but contains the following information directly:
- a class pointer further compressed from 32 bits to 22 bits (explained below),
- the 31-bit Identity Hash Code (unchanged),
- 4 bits reserved for Project Valhalla (new),
- 4 bits for the age of the object (unchanged),
- 1 bit for the so-called “Self Forwarded Tag” (explained below),
- 2 Tag bits (unchanged).
The class pointer has, therefore, been reduced by 10 bits. As we only had to save five bits, five additional bits are now available. Four of these were reserved for Project Valhalla, and the new “Self Forwarded Tag” is stored in one bit.
How Could Class Pointers Be Compressed to 22 Bits?
With the previous 32 bits, we could individually address each position within the 4 GB compressed class space.
For the sake of simplicity, I will illustrate this in the following image with a 256-byte memory area:

As you can see, we need the numbers 0 to 255 to address each position of the memory area. To do this, we need an 8-bit pointer (28 = 256).
But do we really need to be able to address every single position? No, we don't!
Just as a hard disk (whether a conventional one or an SSD) is divided into so-called blocks (usually 4 KB in size), we can also divide the memory area for the class data into blocks. This means we no longer have to address each individual byte but only each block. And so we can address the same memory area with significantly fewer bits.
Here again is the simplified example, in which I divided the 256-byte memory area into 32 blocks of 8 bytes each:

Now, we only need the numbers 0 to 31 to address the same memory area. Therefore, we only need 5-bit pointers (25 = 32). By dividing into blocks, we reduced the memory requirement per pointer from 8 bits to 5 bits.
This also works with the memory area in which the class information is stored.
When using Compact Object Headers, this memory area is divided into 1,024 (=210) byte blocks. The JDK developers chose this value because most classes occupy between half a kilobyte and one kilobyte.
As a reminder, the area is 4 GB in size. This results in 4 × 1,024 × 1,024 × 1,024 / 1,024 blocks, i.e. 4 × 1,024 × 1,024, which is 4,194,304, or 222 blocks. And we can address these with 22 bits!
To turn a 22-bit block number into a pointer, we only have to shift the 22 bits to the left by 10 bits and fill the last 10 bits with zeros, and we have a 32-bit pointer into the 4 GB memory area again:

The division into blocks now leads to class data fragmentation. However, the JDK developers have also considered this: the memory between the classes can also be used by other data structures in the metaspace.
What Is the “Self Forwarded Tag”?
When a garbage collector copies an object to a new memory address, it replaces the upper 62 bits of the mark word in the original object with a pointer to the new memory address and sets the tag bits to 0x11. It then finds the original mark word at the new address.
If the copy operation fails, the mark word is replaced by a pointer to the object itself. As a result, the identity hash code and object age are lost, but this seems to be bearable (unfortunately, I could not find any reliable information about why this is the case, but I will update this section if I find a statement on this).
However, if we were to replace a compact object header with a self-reference, the class pointer would also be lost. As this pointer is essential, a compact object header must never be replaced by such a self-reference.
Instead, the new “Self Forwarded Tag” bit is set.
Conclusion on Compact Object Headers
Compact Object Headers significantly reduce the memory requirements of a Java program by reducing the object headers from 96 bits (12 bytes) to 64 bits (8 bytes).
Not only that: because the objects are smaller, more objects fit into the CPU cache. This results in fewer cache misses – and this also has a positive effect on performance.
Compact Object Headers are still in the experimental stage and must be activated with the following VM option:
-XX:+UnlockExperimentalVMOptions -XX:+UseCompactObjectHeaders
Have you already tested Compact Object Headers? Did it bring the expected improvements? Share your experience in the comments!
Would you like to be informed as soon as Compact Object Headers are finalized and ready for production? Then click here and sign up for the HappyCoders newsletter, in which I will keep you regularly informed about the latest developments from the Java world.